Axtora Labs White Paper
Patented Context-Aware Voice AI Tokenized on Virtuals Protocol
Executive Summary
Axtora Labs is pioneering the next generation of conversational AI through patented, context-aware voice-to-voice agent technology. Our innovative pipeline enables natural, safe, and contextually relevant conversations by integrating curated knowledge bases with advanced LLMs and voice synthesis.
With a granted patent in Hong Kong (HK30101316) and pending applications across major jurisdictions, our technology is positioned to transform multiple industries including education, smart toys, companion robotics, healthcare, and enterprise solutions.
The $AXTORA token, launching via Initial Agent Offering (IAO) on Virtuals Protocol on May 18, 2026, provides token holders with access to AI agent licensing, governance participation, revenue sharing, and priority access to new features.
Problem Statement
Current Limitations in Conversational AI
1. Lack of Context Awareness
Most AI chatbots and voice assistants operate without understanding the specific context or environment in which conversations occur. This leads to generic, often inappropriate responses.
2. Safety Concerns
Open-ended AI systems can generate harmful, biased, or factually incorrect information, especially when interacting with children or vulnerable populations.
3. Limited Personalization
Voice assistants lack the ability to maintain consistent personas or adapt to specific use cases and user demographics.
4. Knowledge Base Limitations
General-purpose LLMs have no mechanism to access curated, domain-specific knowledge controlled by administrators or parents.
5. High Development Costs
Building custom voice AI solutions requires significant investment in infrastructure, training, and integration.
Our Solution
Axtora Labs has developed a patented voice-to-voice AI pipeline that addresses these limitations through:
Context-Aware Processing
Our system retrieves relevant context from a curated database before generating responses, ensuring conversations are contextually appropriate and safe.
Parent/Admin Control
The context database is controlled and curated by administrators or parents, enabling safe, age-appropriate interactions.
Trained Voice Personas
Multiple voice profiles with distinct personalities can be applied, making interactions more engaging and suitable for different use cases.
Modular Architecture
Our pipeline can be integrated into various hardware and software platforms, from educational toys to enterprise solutions.
Cost-Effective Licensing
Token-based licensing model makes our technology accessible to businesses of all sizes.
Technology
The Voice-to-Voice Pipeline
Our patented technology (HK Patent HK30101316) consists of five key stages:
[Voice Input] -> [Voice 2 Text] -> [Context Search] -> [Context Database]
|
[Context + Query] -> [Large Language Model] -> [Text 2 Voice] -> [Voice Output]1. Voice 2 Text
Advanced speech recognition captures user intent and natural language queries with high accuracy across multiple languages and accents.
2. Context Search
Intelligent retrieval system identifies relevant context from the curated database based on the user's query, current situation, and conversation history.
3. Context Database
A safe, appropriate knowledge base controlled by administrators or parents. This database can include:
- Educational content
- Company-specific information
- Product knowledge
- Safety guidelines
- Personal preferences
4. Large Language Model
The AI processes both the retrieved context and user query to generate appropriate, contextually relevant responses. We leverage state-of-the-art LLMs optimized for our specific use cases.
5. Text 2 Voice
Natural voice synthesis with trained personas converts text responses back to natural speech, maintaining consistent character voices and emotional tones.
Technical Advantages
Patent Technical Architecture
Based on a detailed analysis of the provided image, here is a highly technical explanation of the described system and its patented technology.
The Axtora Labs Multimodal Robotic Control Architecture
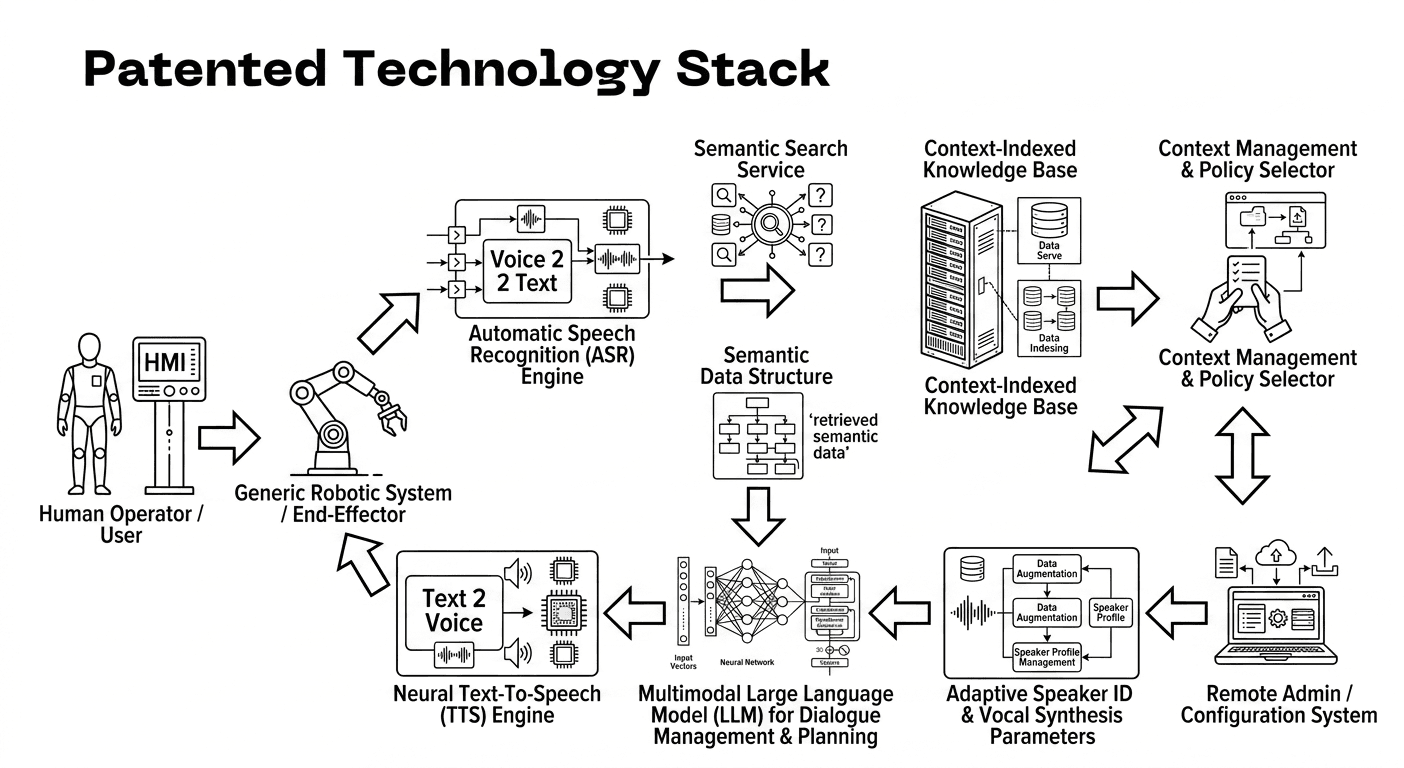
The technology stack illustrated represents a closed-loop, context-aware HMI (Human-Machine Interface) and robotic control system. The patent covers the novel orchestration and feedback loop that enables natural human-robot collaboration via an embodied Large Language Model (LLM). Unlike a typical chatbot, this system integrates high-level natural language understanding with low-level robotic manipulation and biometric personalization in real-time.
The architecture is divided into three functional domains: Data Acquisition & Analysis (Ingress), Cognitive Context Integration (Processing), and Multimodal Action Orchestration (Egress).
Functional Domain 1: Data Acquisition & Analysis (Ingress)
This domain begins at the far left and includes the bottom-right and top-left subsystems. It is responsible for multi-sensor signal input, verification, and conversion into structured data.
1. HMI => Voice to Text ASR Engine
Core Patent Point: The specific sequence and method of converting vocal signal inputs into a formatted, metadata-tagged text object, optimized for a robotic (non-conversational) control vector.
The Human Operator's vocalizations (speech commands) are captured by the HMI (Human-Machine Interface). The HMI passes the analog signal to the <strong>Automatic Speech Recognition (ASR) Engine</strong>.
This ASR module utilizes a Deep Neural Network (DNN) for acoustic modeling to perform transcription. Critically, it does not output just text; it outputs a <strong>Voice to Text Object</strong>. This object contains the transcription, time stamps, and acoustic parameters like confidence scores for phonemes.
2. Adaptive Speaker ID & Vocal Synthesis Parameter Injection (Personalization)
Core Patent Point: The patented method of using speaker identification (SID) as a key for database-driven personalization of the *entire* control and feedback loop.
This subsystem performs dual functions:
- Voice Training (Speaker ID): It uses the input vocal signal to generate or match a unique speaker-profile embedding (e.g., d-vector). This confirms the operator's identity (e.g., ensuring authorization).
- Database Lookup: The speaker ID is used to query the <strong>Context Database</strong> for that operator's specific parameters, which are then passed to the ASR and LLM for customized processing.
Functional Domain 2: Cognitive Context Integration (Processing)
This domain, located at the center-right, is the cognitive heart of the patent. It moves beyond simple command-parsing to create a dynamic situational model.
3. Context Management & Policy Selector (The Context Hub)
Core Patent Point: The patented orchestration logic that binds the ASR output to dynamic, non-verbal system state data (vocal profile, robotic state, environmental selection) and pushes this consolidated "state vector" to the LLM.
This is the critical arbitration node. It simultaneously accepts inputs from multiple sources to synthesize a real-time system context:
- ASR Transcription output.
- Personalized operator profile parameters (e.g., age, preference, permissions) from the Context Database.
- The <strong>Context Selection Object</strong> from the operator's <strong>Context Selection HMI</strong> (e.g., confirming which robot or work cell is being commanded).
This consolidated data is pushed into the <strong>Context Management & Policy Selector</strong>, which performs semantic indexing and vector-space modeling on the incoming data. It synthesizes a high-level context object.
4. Found Context => LLM Ingestion (The Situational Vector)
This subsystem takes the high-level context object and prepares it for LLM digestion. It combines the operator's transcription with the surrounding system state (which robot is being used, who the operator is).
It outputs a "situational vector" (e.g., a structured JSON or embedding vector) that encapsulates: {Operator Command + Operator Profile + Robot ID + Environmental state + Policy constraints}. This vector is fed into the LLM.
Functional Domain 3: Multimodal Action Orchestration (Egress)
This domain, spanning the center and bottom-left, translates cognitive decisions back into physical action and multimodal feedback.
5. Large Language Model (LLM) as a Planner
Core Patent Point: The novel application of an embodied LLM that doesn't generate conversational chat, but instead generates structured action plans and multimodal feedback vectors based on a patented state vector input.
The <strong>Large Language Model (LLM)</strong> receives the situational vector (e.g., {command: "pick up the box on table A", operator: autorizado, robot_id: arm_1, state: idle}).
Rather than a text chat, the LLM's output is a multimodal action plan vector, typically containing:
- Robot Command: A sequence of high-level control operations (e.g., path waypoints, inverse kinematics target, gripper command).
- Speech Feedback Plan: The optimized text string the robot should vocalize to confirm the action.
6. Action Plan Branch (Robotic System Execution)
The action plan vector is sent directly to the commanded <strong>Generic Robotic System (End-Effector)</strong>.
The robot's local controller decodes the high-level commands into joint-space trajectory targets and servo outputs, physically executing the intended task (e.g., picking up the box).
7. Multimodal Feedback Branch (TTS & Personalization)
Core Patent Point: The novel method of real-time, identity-based Text-to-Speech (TTS) adaptation.
Simultaneously, the Speech Feedback Plan text is sent to the <strong>Neural Text-To-Speech (TTS) Engine</strong>.
Crucially, this TTS is *not generic*. It is concurrently fed with the user's specific <strong>Adaptive Speaker Profile</strong> parameters (e.g., d-vector, synthesis pitch, speed) that were retrieved at Domain 1.
The TTS engine synthesizes the text output into an optimized analog audio signal, which is broadcast from the robot's <strong>Speaker Object</strong>. The robot vocalizes its confirmation using a voice pattern adapted *to* or *from* the specific operator.
Summary of Patented Innovation
The specific patented orchestration is the automated binding, indexing, and processing of the multimodal "state vector" that integrates ASR, SID-driven personalization, environment context, and policy constraints into a single input vector for an embodied LLM, which is then translated in parallel into optimized robotic actions and identity-adapted vocal feedback.
Patent Portfolio
Granted Patents
Hong Kong Patent HK30101316
Pending Applications
Government Funding
The Hong Kong Productivity Council (HKPC) Patent Application Grant program provides 90% funding for our global patent expansion:
Market Opportunity
Total Addressable Market (TAM)
Our technology targets a combined market opportunity of $500B+ across multiple sectors:
| Market Segment | Market Size | Year | Growth Rate |
|---|---|---|---|
| Conversational AI | $49.9B | by 2030 | 23.1% CAGR |
| EdTech | $404B | by 2025 | 16.3% CAGR |
| Smart Toys | $42.8B | by 2028 | 18.5% CAGR |
| Companion Robotics | $34B | by 2026 | 22.4% CAGR |
Use Cases
1. Educational Devices
- Interactive learning companions for children
- Language learning tools with native speaker voices
- Homework assistance with curriculum-aligned content
- Special education support with customizable content
2. Smart Toys
- Conversational action figures and dolls
- Educational games with voice interaction
- Storytelling devices with character voices
- Parent-controlled content libraries
3. Companion Robotics
- Elderly care assistants with conversation capabilities
- Therapy robots for mental health support
- Home automation with natural voice interaction
- Pet-like companions with personality
4. Healthcare
- Patient education and medication reminders
- Mental health support with therapeutic conversations
- Caregiver assistance with context-aware information
- Rehabilitation support with personalized content
5. Enterprise Solutions
- Customer service with company-specific knowledge
- Employee training with role-based context
- Sales assistance with product information
- Internal knowledge base access
Competitive Advantages
Legal protection against imitation
Unique capability not found in competitors
Parent/admin oversight for vulnerable users
Innovative licensing model via blockchain
Validated innovation through HKPC grant
The $AXTORA Token
Token Overview
Token Utility
1. Licensing Access
$AXTORA tokens are required to license Axtora Labs' AI technology for commercial deployments. The token-based model ensures:
- Transparent pricing
- Easy integration
- Global accessibility
- Anti-counterfeiting protection
2. Governance Participation
Token holders can vote on:
- Feature development priorities
- Patent portfolio expansion decisions
- Partnership opportunities
- Protocol upgrades
3. Revenue Sharing
A portion of licensing revenue is distributed to token holders:
- Revenue from commercial deployments
- Royalties from patent licensing
- Service fees from API access
- Premium feature subscriptions
4. Priority Access
Token holders receive:
- Early access to new features
- Priority support
- Beta program participation
- Exclusive content and updates
Token Distribution
| Allocation | Percentage | Details |
|---|---|---|
| IAO Public Sale | 40% | Fair launch on Virtuals Protocol |
| Team & Advisors | 20% | 2-year vesting, 6-month cliff |
| Development Fund | 15% | R&D, patents, infrastructure |
| Marketing & Community | 15% | Growth, partnerships, incentives |
| Reserve | 10% | Future opportunities, treasury |
Initial Agent Offering (IAO)
Participation Requirements:
- Web3 wallet compatible with Virtuals Protocol
- $VIRTUAL tokens for participation
- No prior registration needed
Virtuals Protocol Integration
Why Virtuals Protocol?
Axtora Labs chose Virtuals Protocol for the $AXTORA IAO because:
Integration Benefits
Seamless Tokenization
Native support for AI agent tokens
Liquidity Pool
Automatic DEX integration for trading
Staking Mechanisms
Built-in staking for token holders
Governance Tools
Integrated voting and governance systems
Cross-Chain Compatibility
Multi-chain support for broader access
Participation Guide
- Visit app.virtuals.io
- Connect your Web3 wallet
- Ensure you have $VIRTUAL tokens
- Navigate to the $AXTORA IAO
- Participate with your desired amount
Roadmap
2026
Q2
- IAO launch on Virtuals Protocol (May 18)
- Token listing on DEX
- Community building and marketing
- Whitepaper v1.0 release
Q3
- Beta program for early adopters
- First commercial licensing agreements
- Patent filings in Europe, Japan, Korea
- Mobile app development
Q4
- Full commercial launch of licensing platform
- API access for developers
- First hardware integrations
- Staking mechanism implementation
2027
Q1
- Expansion to additional blockchains
- Advanced voice persona library
- Enterprise partnership announcements
- Second whitepaper iteration
Q2
- AI agent marketplace launch
- SDK for third-party developers
- Educational toy partnerships
- Healthcare pilot programs
Q3-Q4
- Global patent portfolio completion
- Additional language support
- Robotics integrations
- Revenue sharing distribution begins
Team
Leadership
Founder & CEO
- Visionary leader with experience in AI and blockchain
- Expertise in voice technology and natural language processing
CTO
- Technical architect with background in machine learning
- Experience in scalable cloud infrastructure
Patent Counsel
- Intellectual property specialist
- Expert in global patent strategy
Advisors
AI/ML Experts
Advisors from leading AI research institutions
Blockchain Specialists
Experienced DeFi and protocol developers
Industry Veterans
Experts from education, toy, and robotics industries
Legal Counsel
Corporate and regulatory compliance experts
Conclusion
Axtora Labs represents a unique opportunity at the intersection of patented AI technology and blockchain tokenization. Our context-aware voice-to-voice AI pipeline addresses critical limitations in current conversational AI solutions, while the $AXTORA token provides innovative access to this technology.
With a granted patent, pending applications across major jurisdictions, government-backed funding, and a $500B+ market opportunity, Axtora Labs is positioned for significant growth.
The IAO launch on Virtuals Protocol on May 18, 2026, offers fair and open access to all participants, enabling broad community involvement in the future of conversational AI.
Join us in building the future of safe, context-aware voice AI.
Contact & Social Media
Disclaimer
This whitepaper is for informational purposes only and does not constitute financial advice. Participation in the IAO involves risk, and individuals should conduct their own research before making any investment decisions. The $AXTORA token is a utility token and not a security.
© 2026 Axtora Labs. All rights reserved.